
{kind=link}
Como pode ser melhorado o desempenho do seu site? Uma alternativa clara seria aprimorar o plano de hospedagem. Isso garantirá mais capacidade de hardware ao seu site, permitindo processar múltiplas solicitações simultaneamente e fornecer os dados de forma mais veloz.
Essa é a percepção geral, porém a verdade é que a realidade costuma ser outra.
Websites contemporâneos are intricate systems comprising multiple components that need to operate harmoniously. If one of them is underperforming, the entire project will be slow to crawl, regardless of how powerful the hosting server may be. One of the most crucial components is the database.
Hoje, iremos examinar de forma detalhada o funcionamento dos bancos de dados, os fatores que os tornam mais lentos e maneiras de otimizá-los.
A relevância da melhoria de performance de banco de dados.
No início da World Wide Web, os sites eram essencialmente compostos por arquivos HTML e mídia. Quando um usuário acessava a URL do site, o servidor web disponibilizava os arquivos para o navegador exibir como texto e imagens. Todos os visitantes viam o mesmo conteúdo e podiam apenas clicar em hiperlinks para explorar outras páginas e imagens.
A situação atual é bastante distinta.
Frequentemente contamos com diversos scripts e aplicativos funcionando ao mesmo tempo para tornar um site básico em algo interativo. Essas ferramentas podem viabilizar funcionalidades simples, como comentários em publicações de blog, mas também têm a capacidade de suportar processos mais complexos, como transações financeiras, pedidos e inscrições. Essas operações dependem fundamentalmente de um banco de dados.
Sempre que um visitante interage com o seu site, a sua aplicação web envia pedidos para o banco de dados, solicitando que seja guardado um novo registo de dados ou que seja fornecido um já existente. A rapidez com que esses pedidos são processados é crucial para o desempenho global do site.
Como é possível determinar se o desempenho do seu banco de dados é eficiente?
Com tantos elementos envolvidos, é desafiador responder a essa questão. Há duas categorias principais de bancos de dados e numerosos sistemas de gerenciamento de banco de dados (SGBDs) distintos, cada um com seus próprios métodos específicos de operação com dados.
Cada indivíduo possui seus próprios instrumentos para acompanhar e mensurar a velocidade, que podem auxiliá-lo a monitorar seu desempenho. No entanto, os elementos da administração do banco de dados que estão sujeitos a análise costumam ser comuns a todos.
Aqui estão as pessoas mencionadas.
- Paráfrase: O tempo de resposta é o período que um banco de dados leva para processar uma consulta e fornecer os resultados ao usuário. Pode-se considerar que não é uma métrica totalmente precisa, pois cada pergunta é única e os tempos médios de resposta variam de acordo com diversos fatores.
Entretanto, essa é a métrica que os usuários mais percebem e é algo essencial a se considerar. Se o tempo médio de resposta aumenta, a qualidade geral do site diminui, portanto é importante agir para resolver isso.
- Paráfrase: A eficiência das consultas é crucial para a rapidez com que o banco de dados fornece as informações solicitadas. Ao acompanhar o desempenho de cada consulta, os responsáveis pelo banco de dados podem identificar lentidões e agir para otimizá-las.
- A transferência de consultas se refere à quantidade de informações que um banco de dados consegue processar simultaneamente. É importante para os administradores conhecer esse volume para adequar o ambiente de hospedagem. Além disso, é essencial que compreendam a forma como os dados são entregues, seja por meio de um pequeno número de grandes consultas ou de várias consultas menores. Essa informação auxilia os administradores a planejar e decidir quais técnicas de otimização serão aplicadas.
- Eventos relacionados a banco de dados envolvem a ação de armazenar, alterar ou remover dados no banco de dados, podendo ser desencadeados por usuários ou aplicativos. Por exemplo, um usuário criando uma nova conta ou um aplicativo deletando registros de erros automaticamente. A ocorrência de muitos eventos simultaneamente pode impactar a performance do banco de dados, especialmente em períodos de alta demanda. Cabe ao administrador do sistema prevenir situações desse tipo.
- Reformulação: A abertura das conexões de banco de dados possibilita a comunicação entre os usuários de aplicativos e o banco de dados. Quanto mais conexões abertas, maior a largura de banda utilizada. No entanto, os novos pedidos de conexão têm um impacto significativo no desempenho e na utilização de recursos.
Por isso, a ideia de agrupamento de conexões está se tornando cada vez mais popular. Um pool de conexões é uma coleção de conexões de banco de dados abertas que podem ser compartilhadas entre usuários e aplicativos de software. Com essa ferramenta, os usuários não precisam fazer pedidos de conexão constantemente, pois podem utilizar uma das conexões já abertas. Isso ajuda a diminuir o tempo de espera e aprimora o desempenho global.
- Problemas com bancos de dados – frequentemente, um problema nesse sistema pode levar à falha total do site. Isso faz com que as páginas fiquem fora do ar e os visitantes se deparem apenas com um fundo branco e uma mensagem de erro, que nem sempre é compreensível para uma pessoa comum.
O visitante provavelmente sairá do seu site e não retornará, o que não é favorável para o seu empreendimento. Por isso, é fundamental detectar e corrigir eventuais falhas no banco de dados o mais rapidamente possível.
Antes de realizar qualquer monitoramento e otimização no banco de dados, é necessário ter conhecimento sobre a tecnologia utilizada por ele.
Selecionando a base de dados apropriada e o sistema de gerenciamento de banco de dados (SGBD).
Selecionar o sistema de gerenciamento de banco de dados adequado é fundamental não só para a performance do seu site, mas também para o desenvolvimento futuro do projeto como um todo. Antes de explicarmos como realizar essa escolha, é necessário esclarecer alguns conceitos.
Antes de mais nada, é necessário abordar os dois principais tipos de bases de dados.
- Bancos de dados relacionais, conhecidos como bancos de dados SQL, operam com a linguagem de consulta estruturada. As informações armazenadas nesse formato são organizadas em tabelas, e o sistema de gerenciamento de banco de dados (DBMS) estabelece relações entre as tabelas para facilitar a recuperação e o acesso ágil e eficiente aos dados.
As bases de dados relacionais adotam uma abordagem simplificada para armazenar informações. A linguagem SQL é de fácil compreensão, e a estrutura evita a duplicação de dados.
Por outro lado, os bancos de dados relacionais são concebidos para funcionar em apenas uma máquina, o que impede sua expansão horizontal. Isso pode se tornar um obstáculo caso o seu projeto cresça a ponto de exigir mais capacidade do que um único servidor pode oferecer.
- Bancos de dados não relacionais, também conhecidos como NoSQL (Not Only SQL), empregam diferentes métodos de armazenamento para guardar informações, como arquivos, colunas e tabelas sem relações, e redes complexas de nós.
Bancos de dados não relacionais possuem a capacidade de armazenar uma ampla variedade de estruturas de dados, além de permitirem escalabilidade horizontal em diversos servidores, o que os torna adequados para sites de grande escala com grande quantidade de dados. Contudo, em um site convencional que lida com conjuntos de dados padronizados, a utilização de um banco de dados não relacional pode ser considerada uma complicação desnecessária.
A decisão entre utilizar um banco de dados relacional ou não-relacional está principalmente relacionada ao tipo de website que se pretende construir. A maioria das plataformas de gerenciamento de conteúdo e construção de sites, como WordPress, Joomla, Drupal, Magento, entre outras, optam por utilizar bancos de dados SQL, e isso se deve a diversas razões.
Primeiramente, várias dessas plataformas têm origens que remontam ao começo dos anos 2000, quando a administração de bancos de dados não relacionais era mais complexa do que é atualmente. A segunda razão, e a mais essencial, é que os dados produzidos pela maioria das aplicações online costumam ser previsíveis. Há uma variedade limitada de tipos de dados, e a estrutura raramente sofre alterações.
No final das contas, a escolha do banco de dados a ser utilizado é determinada pelas necessidades do seu projeto. O mesmo vale para o sistema de gerenciamento de banco de dados (DBMS), que atua como intermediário entre o usuário ou aplicativo e o banco de dados, sendo responsável por processar as consultas entre o cliente e o servidor.
Existem várias alternativas disponíveis. Se optar por utilizar um banco de dados SQL, terá que escolher entre algumas das seguintes opções:
- O sistema de gerenciamento de banco de dados MySQL.
- MariaDB es un sistema de gestión de bases de datos de código abierto compatible con MySQL.
- Servidor de banco de dados da Microsoft chamado SQL Server.
- Resumindo, PostgreSQL
- SQLite es un sistema de gestión de bases de datos relacional que no requiere un servidor, lo que lo hace ideal para aplicaciones de tamaño reducido o uso personal.
A seleção de opções é mais restrita para NoSQL, com MongoDB e Redis sendo as escolhas mais comuns. Além disso, há produtos proprietários, como o Oracle DBMS, que suportam tanto bancos de dados relacionais quanto não relacionais.
Novamente, é essencial verificar quais sistemas de gerenciamento de banco de dados são compatíveis com o software que será utilizado na criação do seu site. Alguns programas são desenvolvidos para funcionar exclusivamente com um tipo específico de banco de dados, ao passo que outros oferecem suporte a diversas opções.
A decisão que você tomará dependerá de diversos aspectos, como a dimensão do seu projeto, suas perspectivas de expansão, as ferramentas utilizadas na construção e o seu orçamento. Avalie cada um deles separadamente e elimine as opções inadequadas até que reste apenas alguns candidatos.
Com a seleção limitada, será necessário analisar e comparar os diversos SGBDs e suas funcionalidades de forma detalhada. Nesse momento, será evidente que algumas disparidades entre os sistemas individuais podem impactar diretamente a performance de seu banco de dados.
Por exemplo, ao comparar diretamente MySQL e MariaDB, percebe-se que o último oferece mais opções de mecanismo de armazenamento e de otimização de velocidade. Assim, se o foco principal for o desempenho, fica claro qual opção é mais vantajosa.
Em última análise, a seleção do sistema de gerenciamento de banco de dados adequado requer uma avaliação detalhada e uma organização criteriosa das prioridades.
A maioria dos serviços de hospedagem gerenciada oferece uma variedade de tecnologias, como um sistema de banco de dados integrado. Devido à popularidade dos bancos de dados relacionais nos sites, é comum encontrar uma configuração padrão que inclui um SQL DBMS.
Em geral, os bancos de dados relacionais são amplamente utilizados, por isso as estratégias de melhoria que vamos apresentar hoje se concentram principalmente nesse tipo de banco de dados.
Índice de Banco de Dados e Melhoria na Eficiência das Consultas
Quanto mais eficiente forem as consultas realizadas no banco de dados, mais rápido será o funcionamento do site. A rapidez na execução das consultas é influenciada por diversos aspectos, como o desempenho do servidor, a quantidade de conexões simultâneas, a configuração do cache de buffer e memória, entre outros fatores.
Entretanto, uma maneira simples de assegurar que os dados sejam entregues rapidamente é através da melhor organização dos mesmos. Ao utilizar um banco de dados relacional, a implementação de uma estratégia de indexação é uma das tarefas mais simples. Para ilustrar como a indexação funciona, vamos considerar um exemplo fictício.
Pense em ter uma planilha de banco de dados contendo 230.000 entradas, equivalente ao número de palavras em um dicionário moderno de inglês. A tabela possui três colunas: uma para IDs, outra para palavras ou frases, e a terceira para suas definições correspondentes, sem estar ordenadas alfabeticamente.
Um cliente deseja descobrir a definição da expressão “banco de dados” na linha 200.000. O sistema de gerenciamento de banco de dados (DBMS) deve carregar a tabela na memória, iniciar do início e percorrer cada linha até localizar a correta. Em resumo, para realizar uma consulta simples, o banco de dados precisa examinar 199.999 linhas. Isso não é a maneira mais eficaz de proceder, sendo essa a razão pela qual os índices são empregados.
Um índice é uma estrutura de dados que fica separada dentro do banco de dados e inclui uma réplica de uma ou mais colunas de uma tabela, juntamente com referências para a localização dos dados correspondentes.
No caso específico mencionado, há um índice que contém uma duplicata da coluna com as palavras, juntamente com os ponteiros que indicam ao sistema de gerenciamento de banco de dados (DBMS) a localização de cada entrada na tabela principal. Por ser uma estrutura de dados independente, é possível organizar as palavras e frases em ordem alfabética sem afetar outros elementos, como os IDs, por exemplo. Os benefícios desse índice são de natureza dupla.
Primeiramente, o sistema de gerenciamento de banco de dados utiliza a ordem alfabética para encontrar rapidamente a palavra no índice. Ao invés de examinar todas as 230.000 palavras e frases, ele simplesmente verifica a entrada de número 115.000 (o ponto médio) no índice para determinar se a palavra “base de dados” vem antes ou depois dessa entrada na ordem alfabética. Por exemplo, se a palavra “microscópio” estiver na 115.000a entrada, então “base de dados” estará localizada acima dela.
O sistema de gerenciamento de banco de dados (DBMS) realizará repetidas buscas no índice para localizar a entrada “base de dados”, o que é mais eficiente do que percorrer todas as linhas de um banco de dados. Isso resultará na exclusão da entrada “Microscópio” e de todas as outras entradas associadas.
Assim que localiza a entrada no índice, o banco de dados obtém as informações necessárias para acessar o bloco de dados que contém os dados relevantes, permitindo recuperar a definição sem precisar carregar toda a tabela de banco de dados em memória. Esse processo torna a operação mais rápida e eficiente.
Alguma desvantagem existe? Sim, ao ser uma estrutura distinta, um índice ocupará espaço adicional de armazenamento. Além disso, é essencial selecionar e combinar com cuidado as colunas que serão adicionadas aos índices. O ideal é indexar informações que são frequentemente consultadas e utilizadas.
Contudo, os benefícios do excelente desempenho superam amplamente quaisquer desvantagens.
Como é possível criar um índice em um banco de dados?
Uma alternativa seria utilizar a instrução SQL CREATE INDEX, a qual é amplamente documentada e não deve representar um grande desafio para indivíduos com certa experiência em SQL. Para aqueles que não se sentem tão à vontade ao lidar com a linha de comando, é preferível utilizar uma ferramenta com interface gráfica, como o phpMyAdmin.
A sequência de ações é a seguinte:
“Para acessar o phpMyAdmin, basta abrir o painel de controle. Caso você utilize o SPanel, o ícone pode ser localizado na seção de Bancos de Dados, presente na página inicial da Interface do Usuário.”
Escolha a base de dados que deseja alterar no menu localizado do lado esquerdo.
A tela principal irá exibir todas as tabelas disponíveis no banco de dados selecionado. Selecione aquela que deseja indexar.
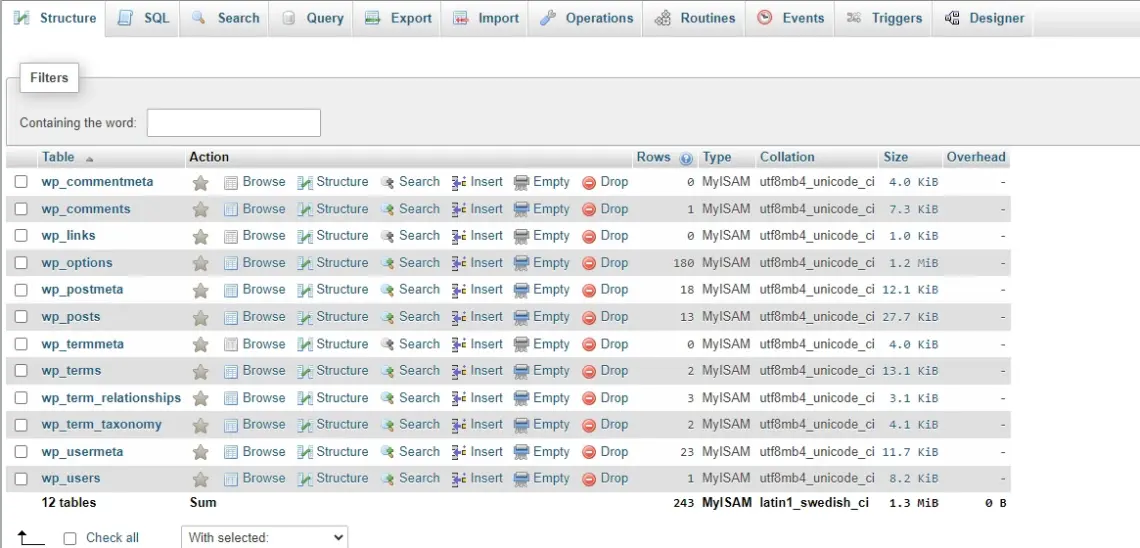
Instruções: Vá até a guia Estrutura. Nessa seção, você terá acesso a todas as colunas presentes na tabela. Utilize as caixas de seleção para marcar aquelas que deseja incluir no índice e, em seguida, pressione o botão Índice localizado abaixo da lista.
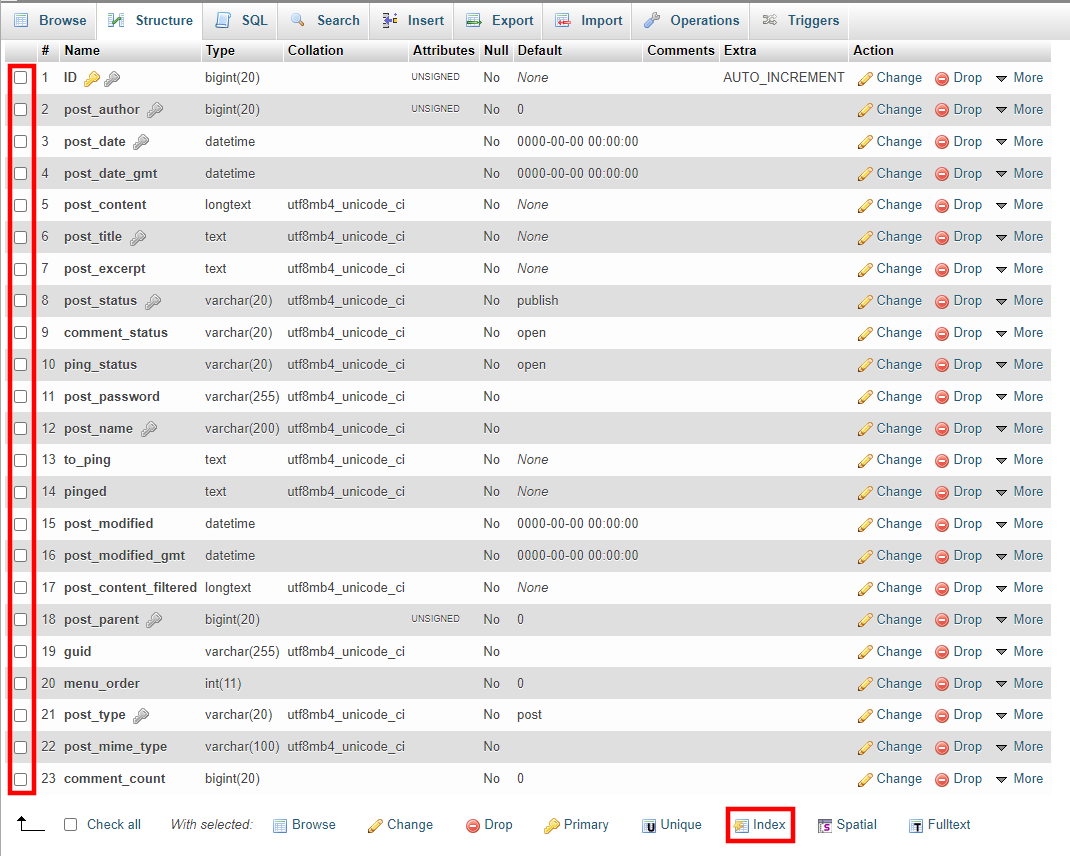
Caso os dados não estejam danificados, o phpMyAdmin mostrará uma notificação indicando que a operação foi concluída com sucesso.
Lembre-se de que ao realizar modificações no banco de dados, você está mexendo em um dos elementos essenciais do seu site. Antes de tentar criar um índice, é recomendável fazer uma cópia de segurança completa do seu site e banco de dados, caso algo não saia como o esperado.
Gerenciamento de memória e armazenamento temporário.
Buffering envolve a otimização da utilização dos recursos de hardware disponíveis, destacando o uso da memória RAM do servidor pelo sistema de gerenciamento de banco de dados para acelerar a execução de consultas.
Sempre que o sistema de gerenciamento de banco de dados precisa acessar dados no banco de dados, ele armazena uma cópia do registro na memória do servidor. Quando há uma solicitação para os mesmos dados, ele busca a cópia na RAM.
Por que está agindo dessa maneira?
Resumindo, a velocidade de acesso aos dados é significativamente mais rápida ao serem lidos da memória em comparação com serem lidos do disco, resultando em um desempenho muito mais rápido, mesmo ao comparar SSDs NVMe com RAM padrão. Isso impacta positivamente as velocidades de carregamento e a experiência do usuário.
Claro, o servidor não possui memória infinita, portanto, o banco de dados não pode armazenar uma quantidade ilimitada de dados. Existe uma quantidade específica de memória reservada para dados de cache, conhecida como buffer. Se o site utiliza o sistema de armazenamento InnoDB, o buffer padrão é de 128MB.
Isso pode não parecer significativo, e alguns de vocês podem se alegrar ao saber que é possível modificá-lo. No entanto, é importante ter em mente que simplesmente aumentar o tamanho do buffer não resolverá todos os problemas.
Isso ocorre em parte devido ao fato de que reservar mais RAM para o buffer pode prejudicar outros elementos essenciais para o bom funcionamento do seu site, privando-os dos recursos necessários. Além disso, não se pode afirmar com certeza que o tamanho do buffer é o principal problema de desempenho.
Por isso, caso ocorra algum problema com o buffer do banco de dados, será importante lidar com a questão de forma mais minuciosa.
Aqui estão alguns sinais que podem ser importantes para você observar atentamente:
- O índice de acerto do buffer pool indica a proporção de consultas respondidas pelo buffer em relação àquelas que precisam acessar o disco. É recomendável manter esse índice o mais alto possível, em torno de 90%, para garantir um processamento eficiente das consultas no banco de dados. Quando uma consulta não encontra a informação na memória, é preciso recorrer ao disco, o que torna o processamento mais lento. Portanto, otimizar a utilização do buffer pool é fundamental para o desempenho do sistema.
- A duração de vida da página é determinada pelo tempo em que cada cópia de um registro armazenado no buffer é removida, sendo mais curta em bases de dados mais ocupadas. O monitoramento da frequência de remoção dos registros do buffer permite calcular a expectativa média de vida da página, uma métrica útil para otimizar o desempenho do banco de dados. Anteriormente, considerava-se aceitável uma expectativa de vida de página de aproximadamente 300 segundos, mas atualmente é mais comum ter essa expectativa para cada 4GB de RAM. Quanto mais ativo o servidor, mais frequentemente as páginas devem ser removidas do buffer, reduzindo sua expectativa de vida e aumentando o número de pedidos não processados, o que afeta negativamente o desempenho do site devido à lentidão do disco.
- A métrica de leitura por segundo da página é importante para monitorar a eficiência da leitura de dados do disco. É recomendado manter esse valor baixo, pois mesmo com o avanço dos SSDs, as consultas no disco do servidor continuam sendo mais lentas. Existem diversas estratégias para reduzir a dependência do disco ao executar consultas em um banco de dados, como utilizar um buffer eficaz para armazenar dados frequentemente acessados e garantir uma indexação adequada para acelerar a localização das informações pelo DBMS.
Controlando o tamanho de armazenamento do banco de dados.
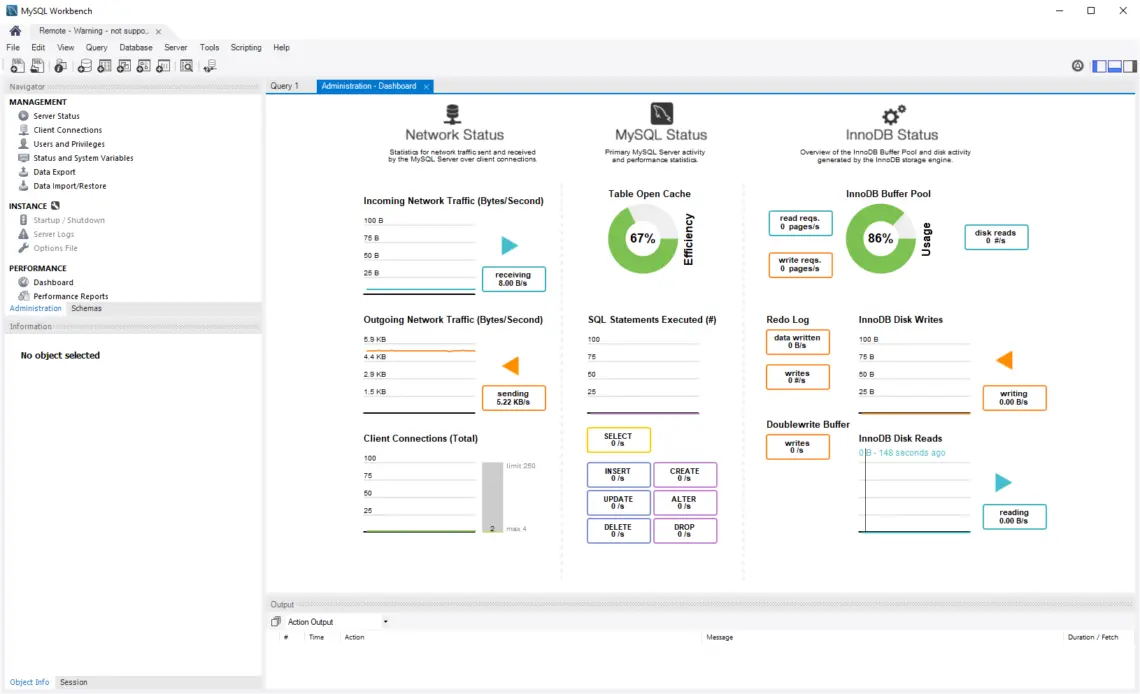
Existem várias formas de acompanhar a saúde do buffer do seu banco de dados. Um exemplo disso é o MySQL Workbench, uma ferramenta gratuita de gestão de bases de dados com interface gráfica, que oferece um painel de desempenho exibindo diversas estatísticas, como a utilização do buffer pool, as operações de leitura/escrita, a taxa de leitura do disco, entre outros.
Alterar o tamanho do buffer é uma tarefa mais complexa, pois requer a modificação do arquivo de configuração principal do MySQL, chamado my.cnf. A localização desse arquivo varia de acordo com o sistema operacional utilizado. Na maioria das distribuições Linux baseadas no Red Hat, ele é encontrado na pasta /etc/. A variável que deve ser adicionada ou modificada depende do mecanismo de armazenamento utilizado. Para o InnoDB, deve-se ajustar a variável innodb_buffer_pool_size, enquanto para bancos de dados MyISAM, a variável é key_buffer_size.
Usando métodos de armazenamento em cache.
No texto anteriormente mencionado, foi explicado que um banco de dados relacional possui uma funcionalidade nativa para armazenar informações na memória, visando aumentar a velocidade. Dessa forma, pode-se dizer que ele já conta com um sistema de cache incorporado, o que poderia tornar a implementação de outras soluções de cache desnecessária.
Isso não é verdade.
A maioria dos sistemas de cache se concentram em armazenar dados estáticos, como imagens, CSS e arquivos JavaScript, porém, alguns sistemas mais avançados também são capazes de armazenar dados dinâmicos do banco de dados na memória RAM do servidor para otimizar a entrega.
Eles ultrapassam o limite convencional em diversas áreas importantes, tais como:
- O cache de armazenamento é um buffer do banco de dados que armazena páginas de informações contendo linhas de tabela e registros. Caches criados por soluções especializadas costumam ser mais bem estruturados.
- O processo de recuperação de informações – as soluções de armazenamento em cache contam com sistemas de chave/valor elaborados para encontrar os dados requeridos, o que leva a uma entrega mais ágil.
- Reformulação: A escalabilidade é uma característica essencial das soluções de cache dedicadas, pois são desenvolvidas para se adaptarem a projetos de diferentes dimensões, proporcionando um desempenho excelente à medida que o site cresce.
Há várias opções de sistemas de cache disponíveis, cada um com pontos positivos e negativos. No entanto, quando se fala em fazer cache de um banco de dados, dois métodos se destacam entre os demais. Vamos explorá-los.
Puedes proporcionar más contexto o el texto completo para que pueda parafrasearlo de manera más efectiva.
O Memcached foi introduzido há mais de vinte anos e desde então se tornou essencial em muitas plataformas de desenvolvimento. É amplamente utilizado por donos de sites devido à sua flexibilidade avançada e capacidade de suportar diversas linguagens de programação. Sua API simplificada facilita a integração com aplicativos, e um plugin dedicado para bancos de dados MySQL agiliza a configuração.
O Memcached tem capacidade para operar em uma arquitetura distribuída, permitindo que os dados em cache sejam armazenados em diversos nós ao mesmo tempo. Embora isso possa parecer oneroso, o uso de tecnologias de containerização e virtualização como Docker e Kubernetes torna essa operação mais acessível.
Simultaneamente, a utilização de múltiplos nós não apenas dividirá a carga e aprimorará o desempenho, mas também reduzirá o tempo de inatividade possível. É por essa razão que, anteriormente, até mesmo grandes plataformas de redes sociais como o Twitter empregaram o Memcached.
Atualmente, contudo, eles também introduziram um novo sistema de armazenamento temporário.
O texto “Redistos” deve ser parafraseado.
Lançado pela primeira vez em 2009, Redis é parecido com o Memcached, sendo open-source e suportado pela maioria dos provedores de hospedagem web. Como o Memcached, ele guarda informações na memória RAM do servidor para proporcionar uma entrega mais ágil.
Diferentemente de seu concorrente no mercado, o Redis armazena os dados na memória de forma persistente, permitindo a recuperação das informações por meio de arquivos de instantâneos e registros após a reinicialização. Com seu sistema de recuperação de dados baseado em valor-chave, o Redis pode ser utilizado como um sistema de gerenciamento de banco de dados não-relacional completo.
Se estiver utilizando um banco de dados SQL, o Redis pode ser integrado como uma opção de armazenamento em cache. O Redis possui suporte para diferentes tipos de dados, ao contrário do Memcached, e a diversidade de linguagens e aplicações compatíveis com o Redis é ainda mais ampla.
De maneira geral, o Redis se destaca por diversas características que o tornam mais robusto e versátil do que o Memcached. Apesar disso, tanto uma quanto a outra solução têm a capacidade de melhorar consideravelmente o desempenho do seu banco de dados, sendo, portanto, uma escolha acertada considerá-las.
Melhoramento da entrada e saída de disco.
Em essência, todas as estratégias de otimização visam, em última instância, diminuir a quantidade de operações de leitura e escrita que o disco precisa realizar (I/O de disco).
Devido aos índices, o DBMS não necessita escanear toda a tabela sempre que um dado é solicitado, e com o uso de buffering, grande parte das consultas são processadas pela memória de acesso aleatório do servidor em vez do disco, que é mais lento.
Entretanto, caso o banco de dados aumente consideravelmente em tamanho, a quantidade de dados se tornará muito extensa, resultando em pesquisas muito aleatórias para que os métodos de otimização mencionados sejam eficazes. Mesmo com os esforços mais intensos, o disco I/O continuará aumentando.
Lidar com essa questão não é tão simples quanto parece, pois diagnosticar o problema requer certo conhecimento técnico e os diversos sistemas de gerenciamento de banco de dados e motores de armazenamento possuem particularidades em suas operações que podem influenciar a entrada e saída de dados.
Não existe uma solução amplamente aceita que possa reduzir a quantidade de operações de leitura e escrita em seu disco. No entanto, há algumas técnicas que tendem a funcionar na maioria das situações:
Melhorando o desempenho de suas tabelas e índices.
Vamos começar com a maneira mais simples de diminuir a sobrecarga do disco. Um banco de dados em funcionamento recebe um grande volume de solicitações para adicionar, alterar e excluir informações armazenadas em tabelas. Quanto mais solicitações desse tipo, mais caóticos os dados se tornam.
A maioria dos sistemas de gerenciamento de banco de dados possui ferramentas automáticas para otimizar as informações, agilizar as consultas e fornecer os dados corretos de forma mais rápida. Por exemplo, no MariaDB e MySQL, essa otimização é realizada com o comando TABLE OPTIMIZE, enquanto no PostgreSQL é feita com o VACUUM.
Sugere-se utilizar regularmente esses recursos como parte da manutenção de rotina do banco de dados. Caso não se sinta à vontade com o uso da linha de comando, ferramentas como o phpMyAdmin podem fornecer as mesmas funcionalidades por meio de uma interface visual.
Aprimorar suas taxas.
Um índice só trará benefícios para a performance de um banco de dados se for configurado corretamente. Deve-se ter atenção especial ao indexar um banco de dados extenso. Ao adicionar uma coluna frequentemente atualizada ao índice, o sistema de gerenciamento de banco de dados precisará realizar mais operações de escrita no disco, principalmente em bancos de dados com muitas linhas.
À medida que sua base de dados aumenta, é importante acompanhar o desempenho. Caso haja uma diminuição na performance, é recomendável revisar os índices utilizados e verificar se os dados que são frequentemente modificados estão sendo indexados. Se estiverem, pode ser interessante desativar alguns índices para observar se isso impactará na velocidade do sistema.
Divisão em partes ou segmentos.
Paritionamento envolve dividir tabelas grandes de banco de dados em fragmentos menores e mais simples de administrar. Os fragmentos individuais podem ser armazenados em sistemas de arquivos diferentes, o que resulta em uma distribuição mais equilibrada da carga e em mais recursos disponíveis para garantir tempos de carregamento mais rápidos. Além disso, dividir a tabela extensa em partes menores ajuda o DBMS a localizar as informações necessárias de forma mais eficiente, melhorando o desempenho global do banco de dados.
Determinando os locais apropriados de verificação.
Um checkpoint é uma instrução para o DBMS transferir as alterações feitas na memória para o armazenamento permanente no HDD ou SSD do servidor. Fazer checkpoints regularmente assegura a preservação das modificações no banco de dados, evitando a perda de dados.
Contudo, toda vez que um ponto de controle é criado, há uma consequente atividade no disco, mas é possível amenizar essa atividade.
Você pode programar os momentos em que são feitos os checkpoints do seu site em períodos de menor movimento, a fim de evitar sobrecarregar o sistema com operações de entrada e saída indesejadas. Além disso, os checkpoints possuem um mecanismo de limite de tempo que interrompe a operação de gravação se estiver demorando muito, o que pode reduzir a pressão no dispositivo de armazenamento principal do seu servidor em momentos de carga elevada.
Elaboração de estrutura de banco de dados
O esquema descreve os componentes essenciais do seu banco de dados (tabelas, registros, campos, índices e dados armazenados) e as conexões entre eles. Quando se compara o banco de dados a uma máquina, o esquema é como um plano que mostra como os elementos individuais são montados e operam juntos no servidor.
É importante ressaltar que, se o esquema não for bem elaborado, poderá ser de difícil compreensão para os administradores de banco de dados e aplicativos de software. Além disso, isso pode tornar a recuperação de dados mais complexa e causar lentidão na execução de consultas. Portanto, o design do esquema é fundamental.
Como você faz a escolha correta?
Primeiramente, inicia-se com um diagrama de relação de entidades (ERD). Um ERD é uma representação gráfica que ilustra a forma como os elementos estão interligados dentro de um sistema. Neste contexto, os elementos referem-se às tabelas, colunas, linhas e entradas, enquanto o sistema é o banco de dados. Embora não seja uma parte intrínseca do banco de dados, o ERD é utilizado pelos administradores de banco de dados para planejar a organização dos dados. Abaixo, é possível observar um exemplo de ERD de um banco de dados típico do WordPress.
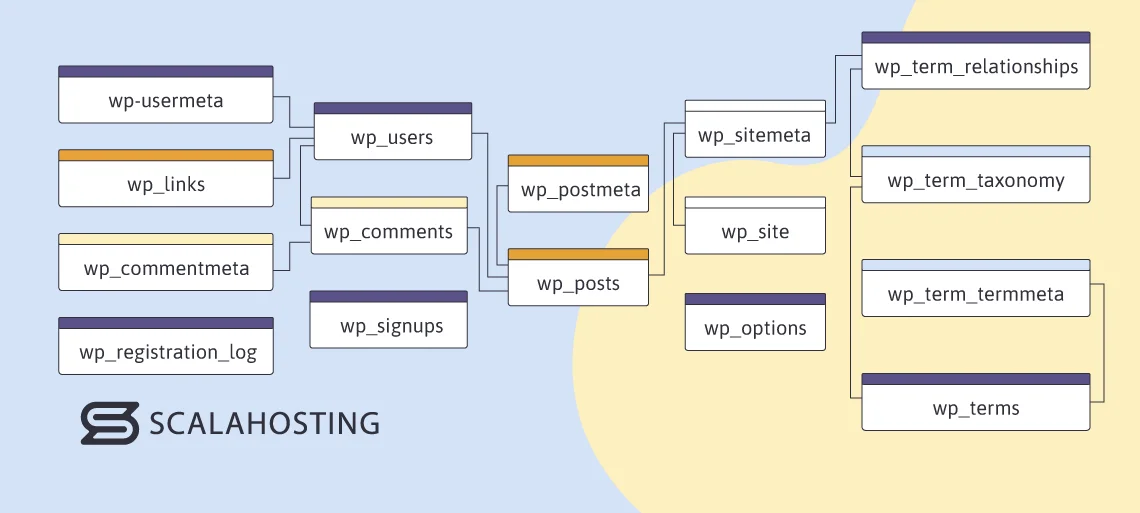
Quando iniciar a criação do seu Diagrama de Entidade-Relacionamento (ERD), você terá à disposição diversos modelos que podem ser utilizados para diferentes tipos de bancos de dados.
Por exemplo, o modelo hierárquico é uma estrutura que se assemelha a uma árvore, com relações bem definidas entre os elementos principais e secundários dentro de entradas individuais. Se as entradas de dados possuem um relacionamento exclusivo, este é o modelo apropriado para sua situação.
O modelo de rede traz a ideia de conjuntos e não segue uma estrutura hierárquica rígida de pais e filhos, sendo útil para organizações de dados com relacionamentos muitos-para-muitos. No entanto, a complexidade de implementar e manter esse modelo é uma desvantagem.
A seleção de um modelo para o seu Diagrama de Entidade-Relacionamento (ERD) e esquema é influenciada por diversos elementos, tais como:
- A quantidade de informações guardadas no banco de dados.
- A quantidade de informações sendo acessada a todo momento.
- A regularidade com que os dados sofrem alterações.
- O tipo de informações necessárias para serem processadas e guardadas.
- As medidas de performance que você estabeleceu.
- As alternativas de expansão que você deseja obter.
Com o modelo selecionado e o design de esquema claro, é hora de colocá-lo em prática. Existem diferentes formas de configurar um novo esquema. Os mais tradicionais optam por redigir as declarações necessárias em um arquivo SQL, enviá-lo para o servidor e executá-lo por meio da linha de comando. Para aqueles que buscam uma alternativa mais amigável, utilizar uma ferramenta como o MySQL Workbench provavelmente será uma opção mais adequada. Após estabelecer a conexão com o servidor de banco de dados, você encontrará o botão correspondente na barra de ferramentas principal.
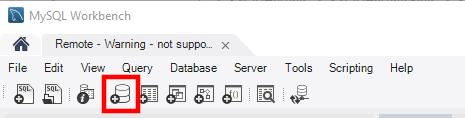
Você precisará inserir o nome do novo esquema, o conjunto de caracteres padrão e a colação. Após clicar em Aplicar, o MySQL Workbench abrirá o editor SQL, permitindo a inserção das declarações necessárias.
Ao planejar a estrutura do seu banco de dados, é importante considerar diversos aspectos que podem contribuir para melhorar o desempenho e facilitar a gestão. Alguns desses aspectos incluem:
- Sugestões para nomear de forma clara – é recomendado seguir algumas diretrizes simples. Ao dar nomes a tabelas e colunas, prefira palavras completas em vez de abreviações, separando-as com sublinhados. Opte por nomes descritivos para tabelas e colunas sempre que puder e evite utilizar palavras reservadas para evitar possíveis erros de sintaxe.
- Utilize o tipo de dados apropriado em seu banco de dados relacional para garantir eficiência. Por exemplo, ao armazenar datas de nascimento dos usuários, utilize o tipo DATE, e ao registrar a data e hora de criação das contas, utilize o tipo DATETIME. É essencial definir corretamente o tipo de dados para cada tabela e registro.
Se os tipos de dados não forem escolhidos corretamente, o banco de dados ocupará mais espaço em disco e as consultas serão menos eficientes em termos de velocidade.
- Manter-se atualizado com as melhores práticas de normalização é fundamental para o design de banco de dados, pois elimina a redundância de dados, simplifica a estrutura do banco e melhora o desempenho das consultas. Existem várias formas de normalização disponíveis, e embora raramente sejam usadas simultaneamente, é útil pesquisar e entender cada uma delas.
Recursos de armazenamento de dados em andamento.
Scaling envolve a inclusão de recursos adicionais de hardware à sua infraestrutura de hospedagem, com o objetivo de aumentar a velocidade do seu site.
A obtenção de mais memória, capacidade de processamento e armazenamento pode resolver certos problemas, mas é importante priorizar a otimização do banco de dados e a implementação de técnicas para aumentar a velocidade antes de considerar a atualização da conta. Não seguir esse passo pode impactar negativamente o projeto de várias maneiras.
Primeiramente, é importante considerar se é necessário atualizar o hardware. Um banco de dados bem otimizado pode funcionar de forma eficiente e processar mais consultas em hardware menos potente do que um banco mal organizado em execução em máquinas mais avançadas. Conforme o banco de dados cresce, a falta de otimização se tornará mais evidente, e mesmo recursos escaláveis podem não ser adequados para garantir velocidades de carregamento rápidas.
Segundo a análise, as estratégias de dimensionamento mais eficazes tendem a tornar a estrutura do banco de dados mais complexa e difícil de manter. Aconselha-se evitar essa complicação adicional, a menos que seja absolutamente necessário.
Dessa forma, é importante ressaltar que a escalabilidade não substitui a importância de aprimorar o design e a operação do banco de dados. Contudo, frequentemente representa a abordagem mais adequada para assegurar a rápida e eficiente execução das consultas.
Existem dois tipos de escalonamento de banco de dados – vertical e horizontal. Vamos aprofundar os conceitos um pouco mais.
- Paráfrase do texto: A escala vertical em bancos de dados refere-se a atualizar o hardware do servidor. A abordagem para isso varia dependendo do tipo de serviço de hospedagem usado. Em um servidor dedicado, é necessário desligar a máquina para trocar os componentes físicos ou migrar o site para um servidor mais poderoso. Por outro lado, em um VPS em nuvem, a virtualização permite escalar o servidor virtual de forma infinita, adicionando núcleos de CPU, RAM ou capacidade de armazenamento com facilidade. Geralmente, basta reiniciar rapidamente o servidor após a atualização, o que não afeta significativamente o tempo de atividade.
- Paráfrase: A escala de banco de dados horizontal, conhecida como fragmentação, é geralmente utilizada em grandes bancos de dados com tabelas extensas. Consiste em dividir uma tabela grande em várias menores e armazená-las em nós distintos, que podem ser máquinas individuais ou instâncias virtuais de contêineres Docker.
De que forma essa situação impacta a performance de sua base de dados?
Inicialmente, ao buscar por um registro específico, o DBMS não percorre uma extensa tabela com milhares de linhas e colunas, mas sim examina um conjunto menor de dados, o que diminui a carga no servidor e contribui para velocidades de carregamento mais rápidas. Além disso, a atividade de leitura e escrita no disco é reduzida, resultando em uma entrega mais ágil dos dados.
A melhoria da disponibilidade de dados também foi notada. Mesmo se um dos nós ficar indisponível, os usuários ainda têm acesso às informações armazenadas em partes da tabela fragmentada que não foram afetadas.
De que forma uma mesa pode ser separada em duas partes?
Novamente, existem duas maneiras de abordagem – horizontal e vertical.
Para exemplificar a distinção, vamos utilizar uma tabela básica com quatro fileiras e cinco colunas. Esta tabela contém os dados dos usuários cadastrados, representados da seguinte maneira:
| ID | Primeiro nome | Sobrenome | Data de nascimento | Local de nascimento |
|---|---|---|---|---|
| 001 | John. | Williams. | 25.09.1990 | Nova Iorque |
| 002 | Jane. | Smith. | 30.04.1989 | San Diego |
| 003 | William. | Jones. | 05.06.1994 | Dallas Dallas |
| 004 | Sam. | Turner | 04.03.1992 | Boston |
Dividir a página horizontalmente implica traçar uma linha na horizontal por meio dela, resultando em duas seções separadas que se assemelham a mesas.
E isso é o seguinte:
Estas duas mesas podem estar localizadas em diferentes locais. A razão para essa divisão vertical é provavelmente compreendida por você. Estamos separando as colunas em duas tabelas que serão armazenadas em servidores distintos. Contudo, devido à necessidade de relacionar os dados de uma tabela com os dados da outra, é essencial utilizar a coluna ID como um identificador.
O desfecho é:
Desculpe, mas preciso de mais contexto ou informações para poder parafrasear o texto. Poderia fornecer mais detalhes ou o texto completo para que eu possa ajudar melhor?
A proposta é que o sistema de gerenciamento de banco de dados possui menos registros para examinar, o que possibilita localizar as informações essenciais de maneira mais ágil.
Resumo, encerramento.
Paráfrase: Melhorar a velocidade de um banco de dados pode parecer intimidante, como evidenciado pelo detalhado relatório apresentado anteriormente. O processo pode ser complexo, pois diversos aspectos influenciam o desempenho, tornando desafiador para um único responsável pelo site corrigi-los todos.
Uma vantagem do uso de um serviço VPS gerenciado é que você pode contar com profissionais para lidar com esses aspectos para você. O sistema de gerenciamento de banco de dados (DBMS) é uma parte integrada do pacote oferecido e normalmente é configurado para funcionar com as principais aplicações e operar de forma otimizada.
Entretanto, é importante compreender o funcionamento e as possíveis maneiras de aumentar a sua velocidade, mesmo que o relatório detalhado fornecido acima contenha todas as informações necessárias para isso.

Perguntas comuns
Como faço para avaliar o desempenho do meu VPS?
Se o servidor não estiver funcionando adequadamente, é provável que você perceba isso ao acessar suas páginas. Nesse caso, é recomendável utilizar uma das diversas ferramentas de teste de velocidade de página disponíveis online. Ao usá-las de forma regular, você poderá estabelecer um padrão para a velocidade ideal do seu site. Assim, ao identificar qualquer desvio desse referencial, será possível detectar a diferença antes que seja notada pelo usuário.
R: De que forma você melhora a eficiência do seu banco de dados?
Ao adquirir um melhor conhecimento sobre o funcionamento de seu banco de dados, você será capaz de compreender as medidas necessárias para otimizá-lo. Isso o auxiliará a dominar a aplicação de estratégias como indexação e caching, demonstrando como tais técnicas contribuem para melhorar o desempenho do sistema.
Qual é a finalidade de melhorar o desempenho do banco de dados?
Resposta: Muitos dos elementos visíveis em um site comum são guardados no banco de dados. Quanto mais eficiente for a entrega desses dados, mais rápida será a sua página. E uma página mais ágil contribui para uma experiência do usuário aprimorada, algo essencial em qualquer projeto online.